|
Optical Character Recognition, OCR for short, has been a great boon to genealogists. Using OCR technology, organizations have scanned and digitized an array of printed material and made it available on the internet. It is definitely a timesaver to have the computer read a newspaper for you and locating all instances of the name you’re searching for. But just how good a reader is that computer? OCR by its nature reads letters one by one. If just one letter in the word you’re searching for was poorly inked, either too lightly or too heavily… if there was even a tiny smudge of dirt on the sheet before it was scanned… if the newspaper was first microfilmed, and then scanned… all of these things can adversely impact the computer’s ability to correctly read the words. Spend a bit of time learning about OCR using newspaper and book sites that display the OCR interpretation alongside the actual page image. These include the California Digital Newspaper Collection (www.cdnc.ucr.edu) and the Hoosier State Chronicles (newspapers.library.in.gov). Even if you don’t have ancestors who are likely to be mentioned in these collections, you’ll begin to learn that a lowercase “y” is often misread as a “v” or the letter combination of “rn” is misread as “m” turning the word “Ahern” into “Ahem.” Then when you go back to searching in those collections that do hold the newspapers from your ancestor Henry Ahern’s hometown, make sure you search for Henrv Ahem as well. 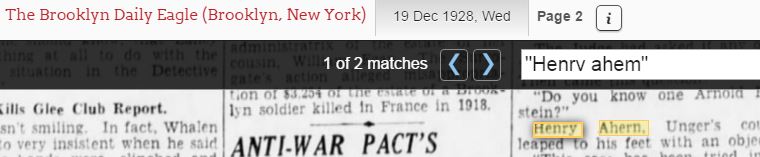
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
AuthorMary Kircher Roddy is a genealogist, writer and lecturer, always looking for the story. Her blog is a combination of the stories she has found and the tools she used to find them. Archives
April 2021
Categories
All

|
